Abstract
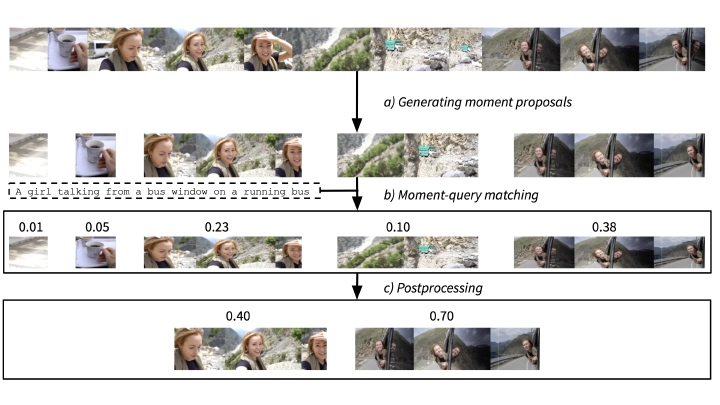
For the majority of the machine learning community, the expensive nature of collecting high-quality human-annotated data and the inability to efficiently finetune very large state-of-the-art pretrained models on limited compute are major bottlenecks for building models for new tasks. We propose a zero-shot simple approach for one such task, Video Moment Retrieval (VMR), that does not perform any additional finetuning and simply repurposes off-the-shelf models trained on other tasks. Our three-step approach consists of moment proposal, moment-query matching and postprocessing, all using only off-the-shelf models. On the QVHighlights benchmark for VMR, we vastly improve performance of previous zero-shot approaches by at least 2.5x on all metrics and reduce the gap between zero-shot and state-of-the-art supervised by over 74%. Further, we also show that our zero-shot approach beats non-pretrained supervised models on the Recall metrics and comes very close on mAP metrics; and that it also performs better than the best pretrained supervised model on shorter moments. Finally, we ablate and analyze our results and propose interesting future directions.